Chapter 5 Clustering
5.1 Overview
Clustering is an unsupervised learning procedure that is used to empirically define groups of cells with similar expression profiles. Its primary purpose is to summarize complex scRNA-seq data into a digestible format for human interpretation. This allows us to describe population heterogeneity in terms of discrete labels that are easily understood, rather than attempting to comprehend the high-dimensional manifold on which the cells truly reside. After annotation based on marker genes, the clusters can be treated as proxies for more abstract biological concepts such as cell types or states.
At this point, it is helpful to realize that clustering, like a microscope, is simply a tool to explore the data. We can zoom in and out by changing the resolution of the clustering parameters, and we can experiment with different clustering algorithms to obtain alternative perspectives of the data. This iterative approach is entirely permissible given that data exploration constitutes the majority of the scRNA-seq data analysis workflow. As such, questions about the “correctness” of the clusters or the “true” number of clusters are usually meaningless. We can define as many clusters as we like, with whatever algorithm we like - each clustering will represent its own partitioning of the high-dimensional expression space, and is as “real” as any other clustering.
A more relevant question is “how well do the clusters approximate the cell types or states of interest?” Unfortunately, this is difficult to answer given the context-dependent interpretation of the underlying biology. Some analysts will be satisfied with resolution of the major cell types; other analysts may want resolution of subtypes; and others still may require resolution of different states (e.g., metabolic activity, stress) within those subtypes. Moreover, two clusterings can be highly inconsistent yet both valid, simply partitioning the cells based on different aspects of biology. Indeed, asking for an unqualified “best” clustering is akin to asking for the best magnification on a microscope without any context.
Regardless of the exact method used, clustering is a critical step for extracting biological insights from scRNA-seq data. Here, we demonstrate the application of several commonly used methods with the 10X PBMC dataset.
#--- loading ---#
library(DropletTestFiles)
raw.path <- getTestFile("tenx-2.1.0-pbmc4k/1.0.0/raw.tar.gz")
out.path <- file.path(tempdir(), "pbmc4k")
untar(raw.path, exdir=out.path)
library(DropletUtils)
fname <- file.path(out.path, "raw_gene_bc_matrices/GRCh38")
sce.pbmc <- read10xCounts(fname, col.names=TRUE)
#--- gene-annotation ---#
library(scater)
rownames(sce.pbmc) <- uniquifyFeatureNames(
rowData(sce.pbmc)$ID, rowData(sce.pbmc)$Symbol)
library(EnsDb.Hsapiens.v86)
location <- mapIds(EnsDb.Hsapiens.v86, keys=rowData(sce.pbmc)$ID,
column="SEQNAME", keytype="GENEID")
#--- cell-detection ---#
set.seed(100)
e.out <- emptyDrops(counts(sce.pbmc))
sce.pbmc <- sce.pbmc[,which(e.out$FDR <= 0.001)]
#--- quality-control ---#
stats <- perCellQCMetrics(sce.pbmc, subsets=list(Mito=which(location=="MT")))
high.mito <- isOutlier(stats$subsets_Mito_percent, type="higher")
sce.pbmc <- sce.pbmc[,!high.mito]
#--- normalization ---#
library(scran)
set.seed(1000)
clusters <- quickCluster(sce.pbmc)
sce.pbmc <- computeSumFactors(sce.pbmc, cluster=clusters)
sce.pbmc <- logNormCounts(sce.pbmc)
#--- variance-modelling ---#
set.seed(1001)
dec.pbmc <- modelGeneVarByPoisson(sce.pbmc)
top.pbmc <- getTopHVGs(dec.pbmc, prop=0.1)
#--- dimensionality-reduction ---#
set.seed(10000)
sce.pbmc <- denoisePCA(sce.pbmc, subset.row=top.pbmc, technical=dec.pbmc)
set.seed(100000)
sce.pbmc <- runTSNE(sce.pbmc, dimred="PCA")
set.seed(1000000)
sce.pbmc <- runUMAP(sce.pbmc, dimred="PCA")## class: SingleCellExperiment
## dim: 33694 3985
## metadata(1): Samples
## assays(2): counts logcounts
## rownames(33694): RP11-34P13.3 FAM138A ... AC213203.1 FAM231B
## rowData names(2): ID Symbol
## colnames(3985): AAACCTGAGAAGGCCT-1 AAACCTGAGACAGACC-1 ...
## TTTGTCAGTTAAGACA-1 TTTGTCATCCCAAGAT-1
## colData names(3): Sample Barcode sizeFactor
## reducedDimNames(3): PCA TSNE UMAP
## mainExpName: NULL
## altExpNames(0):5.2 Graph-based clustering
5.2.1 Background
Popularized by its use in Seurat, graph-based clustering is a flexible and scalable technique for clustering large scRNA-seq datasets. We first build a graph where each node is a cell that is connected to its nearest neighbors in the high-dimensional space. Edges are weighted based on the similarity between the cells involved, with higher weight given to cells that are more closely related. We then apply algorithms to identify “communities” of cells that are more connected to cells in the same community than they are to cells of different communities. Each community represents a cluster that we can use for downstream interpretation.
The major advantage of graph-based clustering lies in its scalability. It only requires a \(k\)-nearest neighbor search that can be done in log-linear time on average, in contrast to hierachical clustering methods with runtimes that are quadratic with respect to the number of cells. Graph construction avoids making strong assumptions about the shape of the clusters or the distribution of cells within each cluster, compared to other methods like \(k\)-means (that favor spherical clusters) or Gaussian mixture models (that require normality). From a practical perspective, each cell is forcibly connected to a minimum number of neighboring cells, which reduces the risk of generating many uninformative clusters consisting of one or two outlier cells.
The main drawback of graph-based methods is that, after graph construction, no information is retained about relationships beyond the neighboring cells1. This has some practical consequences in datasets that exhibit differences in cell density, as more steps through the graph are required to move the same distance through a region of higher cell density. From the perspective of community detection algorithms, this effect “inflates” the high-density regions such that any internal substructure or noise is more likely to cause formation of subclusters. The resolution of clustering thus becomes dependent on the density of cells, which can occasionally be misleading if it overstates the heterogeneity in the data.
5.2.2 Implementation
To demonstrate, we use the clusterCells() function in scran on PBMC dataset.
All calculations are performed using the top PCs to take advantage of data compression and denoising.
This function returns a vector containing cluster assignments for each cell in our SingleCellExperiment object.
## nn.clusters
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## 205 508 541 56 374 125 46 432 302 867 47 155 166 61 84 16We assign the cluster assignments back into our SingleCellExperiment object as a factor in the column metadata.
This allows us to conveniently visualize the distribution of clusters in a \(t\)-SNE plot (Figure 5.1).
library(scater)
colLabels(sce.pbmc) <- nn.clusters
plotReducedDim(sce.pbmc, "TSNE", colour_by="label")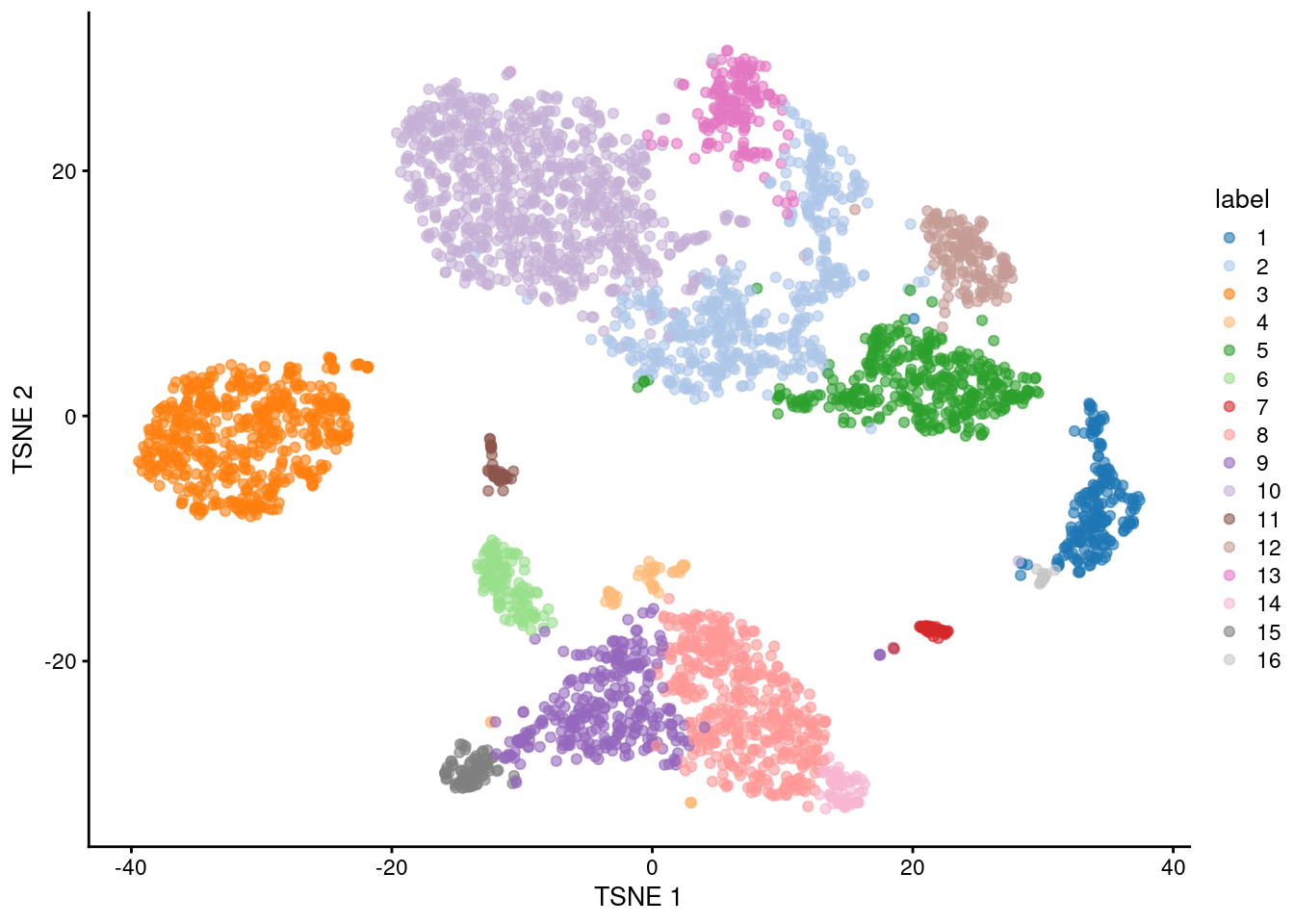
Figure 5.1: \(t\)-SNE plot of the 10X PBMC dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from graph-based clustering.
By default, clusterCells() uses the 10 nearest neighbors of each cell to construct a shared nearest neighbor graph.
Two cells are connected by an edge if any of their nearest neighbors are shared,
with the edge weight defined from the highest average rank of the shared neighbors (Xu and Su 2015).
The Walktrap method from the igraph package is then used to identify communities.
If we wanted to explicitly specify all of these parameters, we would use the more verbose call below.
This uses a SNNGraphParam object from the bluster package to instruct clusterCells() to detect communities from a shared nearest-neighbor graph with the specified parameters.
The appeal of this interface is that it allows us to easily switch to a different clustering algorithm by simply changing the BLUSPARAM= argument,
as we will demonstrate later in the chapter.
library(bluster)
nn.clusters2 <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=SNNGraphParam(k=10, type="rank", cluster.fun="walktrap"))
table(nn.clusters2)## nn.clusters2
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## 205 508 541 56 374 125 46 432 302 867 47 155 166 61 84 16We can also obtain the graph itself by specifying full=TRUE in the clusterCells() call.
Doing so will return all intermediate structures that are used during clustering, including a graph object from the igraph package.
This graph can be visualized using a force-directed layout (Figure 5.2), closely related to \(t\)-SNE and UMAP,
though which of these is the most aesthetically pleasing is left to the eye of the beholder.
## IGRAPH f4087a6 U-W- 3985 133130 --
## + attr: weight (e/n)
## + edges from f4087a6:
## [1] 4--12 8--13 11--15 12--17 4--17 12--18 17--18 8--20 1--21 8--23
## [11] 2--25 17--27 18--27 11--30 15--30 10--31 25--33 2--33 19--37 9--38
## [21] 23--41 4--43 12--43 17--43 21--45 2--47 33--47 22--48 18--49 22--51
## [31] 48--51 16--52 11--54 15--54 30--54 26--57 21--58 47--58 52--59 13--59
## [41] 23--60 9--60 41--60 52--60 22--61 51--61 48--61 55--63 22--64 61--64
## [51] 48--64 51--64 1--65 42--67 16--68 55--69 50--70 59--70 40--71 55--72
## [61] 63--73 39--75 69--75 30--76 11--76 15--76 8--78 41--78 20--79 8--79
## [71] 6--82 76--82 15--82 11--85 30--85 76--85 15--85 54--85 14--87 66--87
## + ... omitted several edgesset.seed(11000)
reducedDim(sce.pbmc, "force") <- igraph::layout_with_fr(nn.clust.info$objects$graph)
plotReducedDim(sce.pbmc, colour_by="label", dimred="force")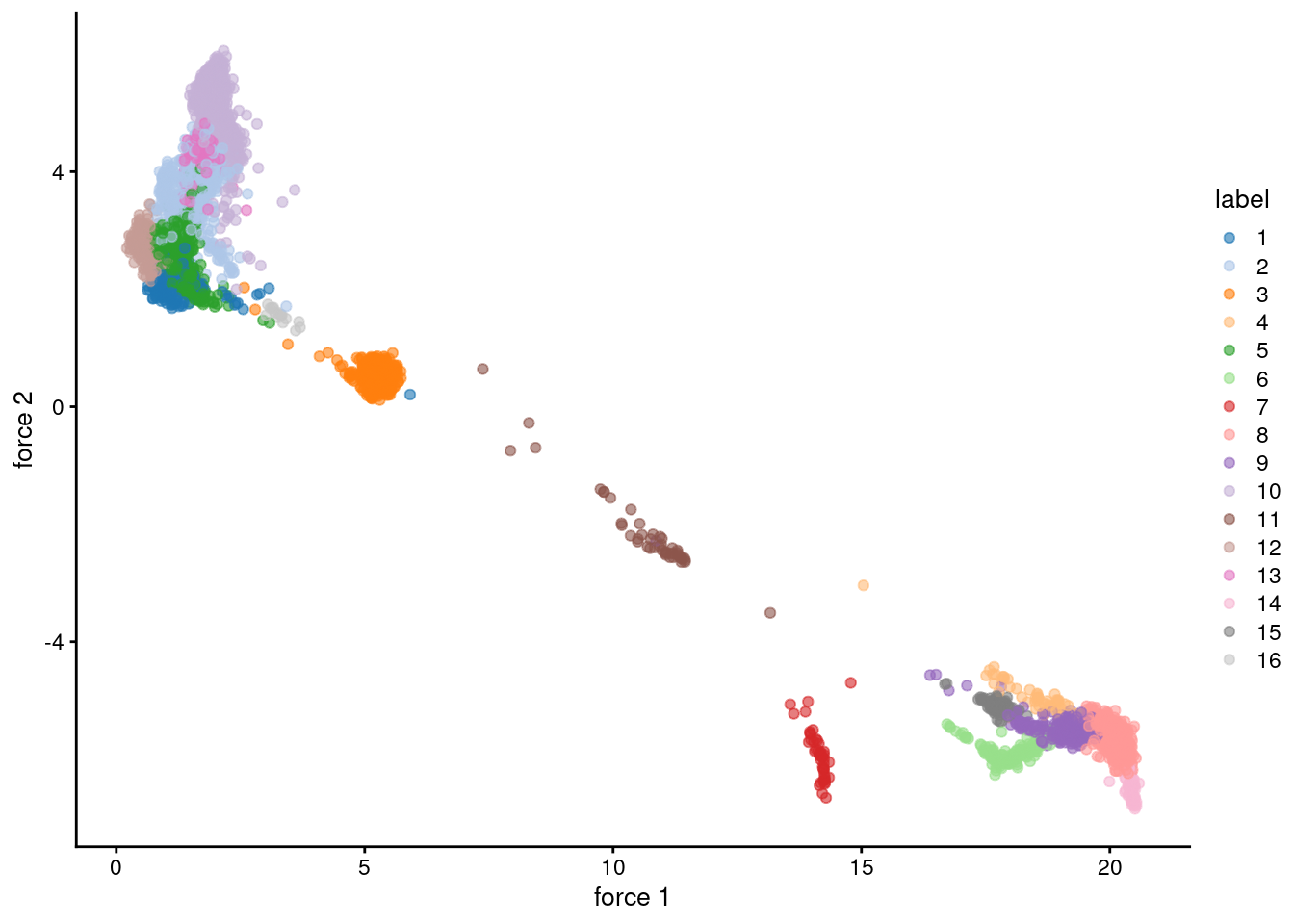
Figure 5.2: Force-directed layout for the shared nearest-neighbor graph of the PBMC dataset. Each point represents a cell and is coloured according to its assigned cluster identity.
In addition, the graph can be used to generate detailed diagnostics on the behavior of the graph-based clustering (Advanced Section 5.2.5).
5.2.3 Adjusting the parameters
A graph-based clustering method has several key parameters:
- How many neighbors are considered when constructing the graph.
- What scheme is used to weight the edges.
- Which community detection algorithm is used to define the clusters.
One of the most important parameters is k, the number of nearest neighbors used to construct the graph.
This controls the resolution of the clustering where higher k yields a more inter-connected graph and broader clusters.
Users can exploit this by experimenting with different values of k to obtain a satisfactory resolution.
# More resolved.
clust.5 <- clusterCells(sce.pbmc, use.dimred="PCA", BLUSPARAM=NNGraphParam(k=5))
table(clust.5)## clust.5
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
## 523 302 125 45 172 573 249 439 293 95 772 142 38 18 62 38 30 16 15 9
## 21 22
## 16 13# Less resolved.
clust.50 <- clusterCells(sce.pbmc, use.dimred="PCA", BLUSPARAM=NNGraphParam(k=50))
table(clust.50)## clust.50
## 1 2 3 4 5 6 7 8 9 10
## 869 514 194 478 539 944 138 175 89 45Further tweaking can be performed by changing the edge weighting scheme during graph construction.
Setting type="number" will weight edges based on the number of nearest neighbors that are shared between two cells.
Similarly, type="jaccard" will weight edges according to the Jaccard index of the two sets of neighbors.
We can also disable weighting altogether by using a simple \(k\)-nearest neighbor graph, which is occasionally useful for downstream graph operations that do not support weights.
clust.num <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(type="number"))
table(clust.num)## clust.num
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
## 199 541 354 294 458 123 47 45 170 397 838 150 40 80 136 50 31 16 16clust.jaccard <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(type="jaccard"))
table(clust.jaccard)## clust.jaccard
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
## 201 541 740 233 352 47 124 841 45 361 40 154 80 61 133 16 16## clust.none
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
## 541 446 54 170 699 45 126 172 128 907 286 47 158 137 54 15The community detection can be performed by using any of the algorithms provided by igraph. We have already mentioned the Walktrap approach, but many others are available to choose from:
clust.walktrap <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(cluster.fun="walktrap"))
clust.louvain <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(cluster.fun="louvain"))
clust.infomap <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(cluster.fun="infomap"))
clust.fast <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(cluster.fun="fast_greedy"))
clust.labprop <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(cluster.fun="label_prop"))
clust.eigen <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=NNGraphParam(cluster.fun="leading_eigen"))It is straightforward to compare two clustering strategies to see how they differ (Advanced Section 5.3). For example, Figure 5.3 suggests that Infomap yields finer clusters than Walktrap while fast-greedy yields coarser clusters.
library(pheatmap)
# Using a large pseudo-count for a smoother color transition
# between 0 and 1 cell in each 'tab'.
tab <- table(paste("Infomap", clust.infomap),
paste("Walktrap", clust.walktrap))
ivw <- pheatmap(log10(tab+10), main="Infomap vs Walktrap",
color=viridis::viridis(100), silent=TRUE)
tab <- table(paste("Fast", clust.fast),
paste("Walktrap", clust.walktrap))
fvw <- pheatmap(log10(tab+10), main="Fast-greedy vs Walktrap",
color=viridis::viridis(100), silent=TRUE)
gridExtra::grid.arrange(ivw[[4]], fvw[[4]])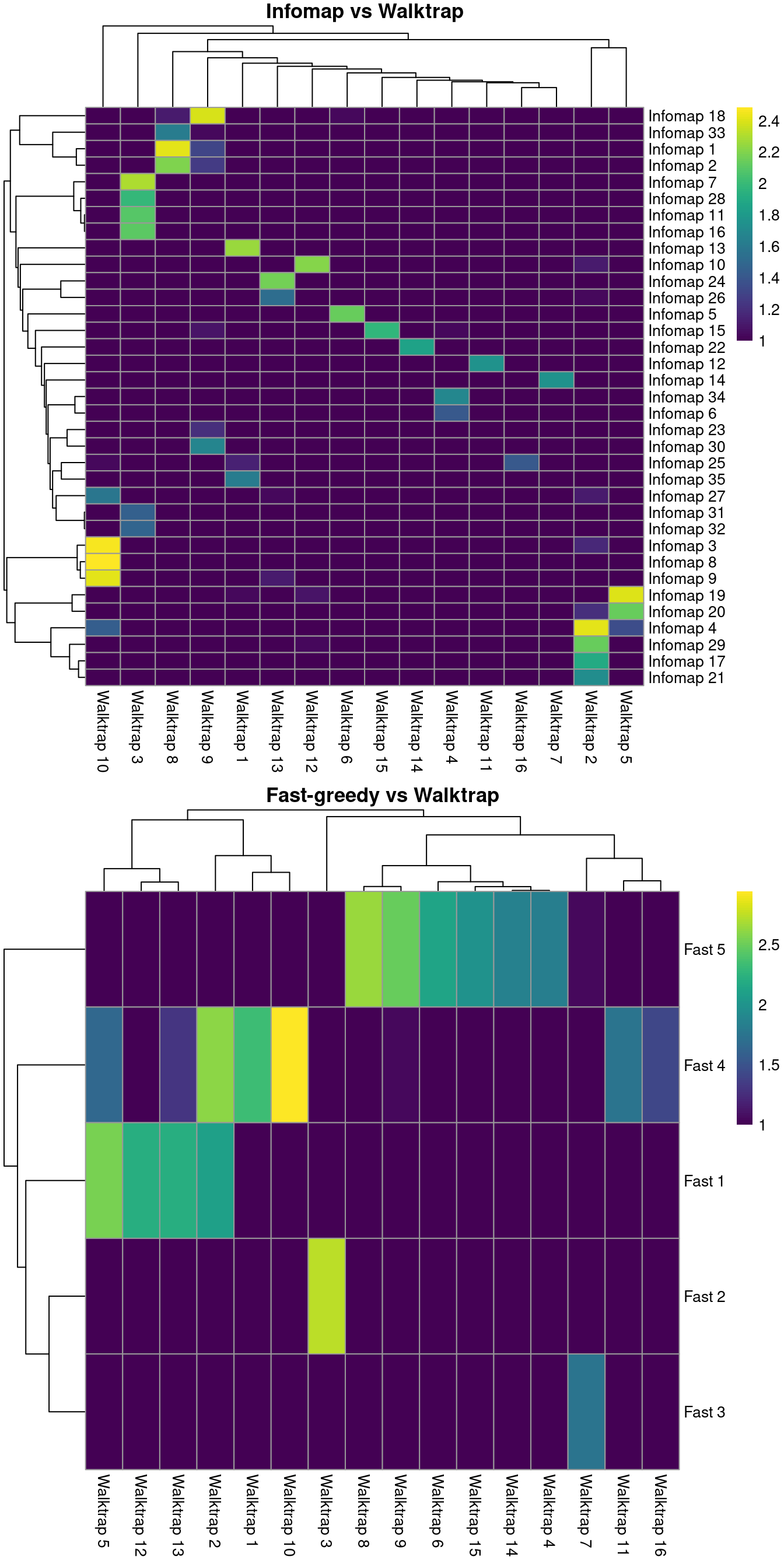
Figure 5.3: Number of cells assigned to combinations of cluster labels with different community detection algorithms in the PBMC dataset. Each entry of each heatmap represents a pair of labels, coloured proportionally to the log-number of cells with those labels.
Pipelines involving scran default to rank-based weights followed by Walktrap clustering. In contrast, Seurat uses Jaccard-based weights followed by Louvain clustering. Both of these strategies work well, and it is likely that the same could be said for many other combinations of weighting schemes and community detection algorithms.
5.3 Vector quantization with \(k\)-means
5.3.1 Background
Vector quantization partitions observations into groups where each group is associated with a representative point, i.e., vector in the coordinate space. This is a type of clustering that primarily aims to compress data by replacing many points with a single representative. The representatives can then be treated as “samples” for further analysis, reducing the number of samples and computational work in later steps like, e.g., trajectory reconstruction (Ji and Ji 2016). This approach will also eliminate differences in cell density across the expression space, ensuring that the most abundant cell type does not dominate downstream results.
\(k\)-means clustering is a classic vector quantization technique that divides cells into \(k\) clusters. Each cell is assigned to the cluster with the closest centroid, which is done by minimizing the within-cluster sum of squares using a random starting configuration for the \(k\) centroids. We usually set \(k\) to a large value such as the square root of the number of cells to obtain fine-grained clusters. These are not meant to be interpreted directly, but rather, the centroids are used in downstream steps for faster computation. The main advantage of this approach lies in its speed, given the simplicity and ease of implementation of the algorithm.
5.3.2 Implementation
We supply a KmeansParam object in clusterCells() to perform \(k\)-means clustering with the specified number of clusters in centers=.
We again use our top PCs after setting the random seed to ensure that the results are reproducible.
In general, the \(k\)-means clusters correspond to the visual clusters on the \(t\)-SNE plot in Figure 5.4, though there are some divergences that are not observed in, say, Figure 5.1.
(This is at least partially due to the fact that \(t\)-SNE is itself graph-based and so will naturally agree more with a graph-based clustering strategy.)
set.seed(100)
clust.kmeans <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=KmeansParam(centers=10))
table(clust.kmeans)## clust.kmeans
## 1 2 3 4 5 6 7 8 9 10
## 548 46 408 270 539 199 148 783 163 881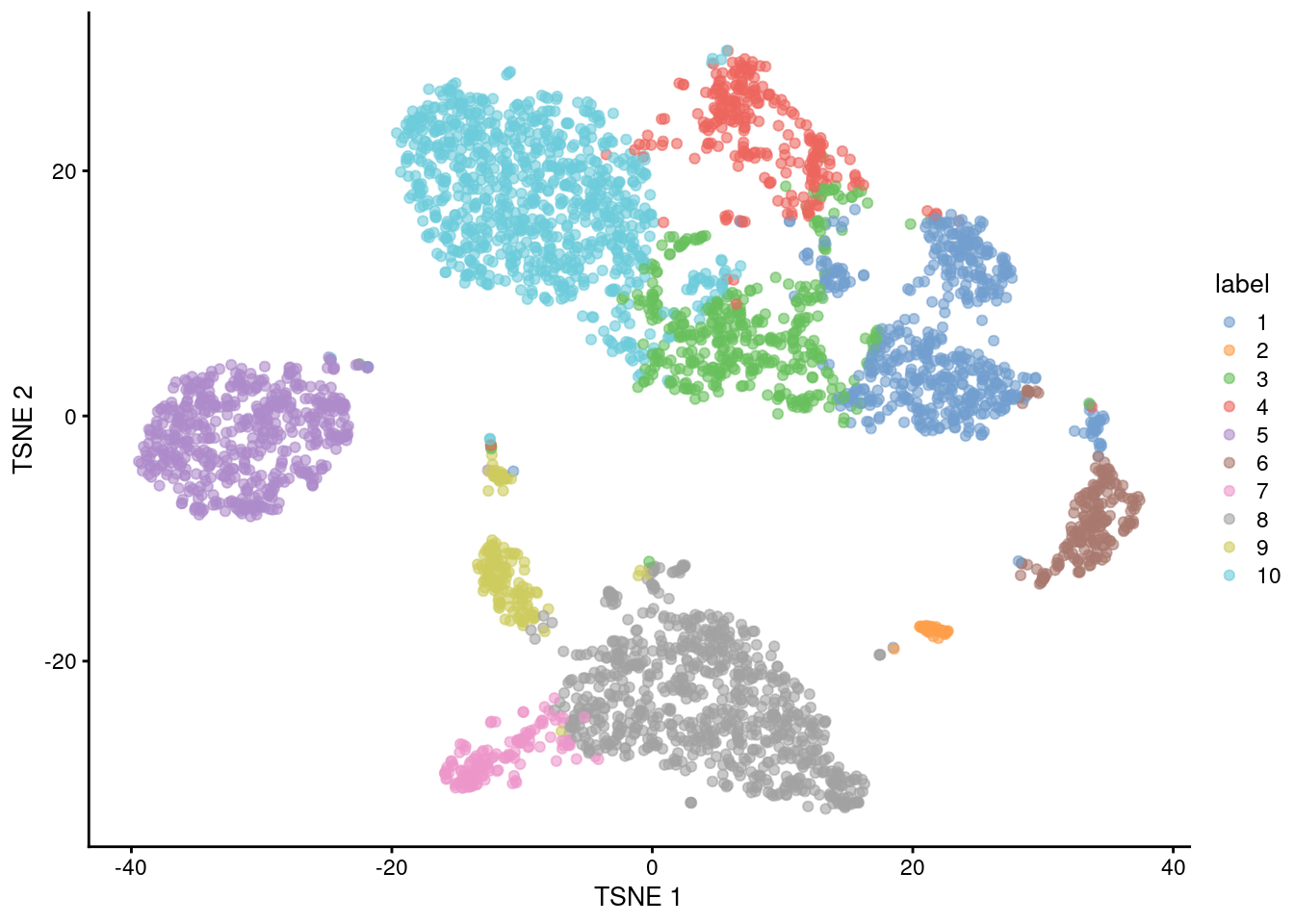
Figure 5.4: \(t\)-SNE plot of the 10X PBMC dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from \(k\)-means clustering.
If we were so inclined, we could obtain a “reasonable” choice of \(k\) by computing the gap statistic using methods from the cluster package. A more practical use of \(k\)-means is to deliberately set \(k\) to a large value to achieve overclustering. This will forcibly partition cells inside broad clusters that do not have well-defined internal structure. For example, we might be interested in the change in expression from one “side” of a cluster to the other, but the lack of any clear separation within the cluster makes it difficult to separate with graph-based methods, even at the highest resolution. \(k\)-means has no such problems and will readily split these broad clusters for greater resolution.
set.seed(100)
clust.kmeans2 <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=KmeansParam(centers=20))
table(clust.kmeans2)## clust.kmeans2
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
## 243 28 202 361 282 166 388 150 114 537 170 96 46 131 162 118 201 257 288 45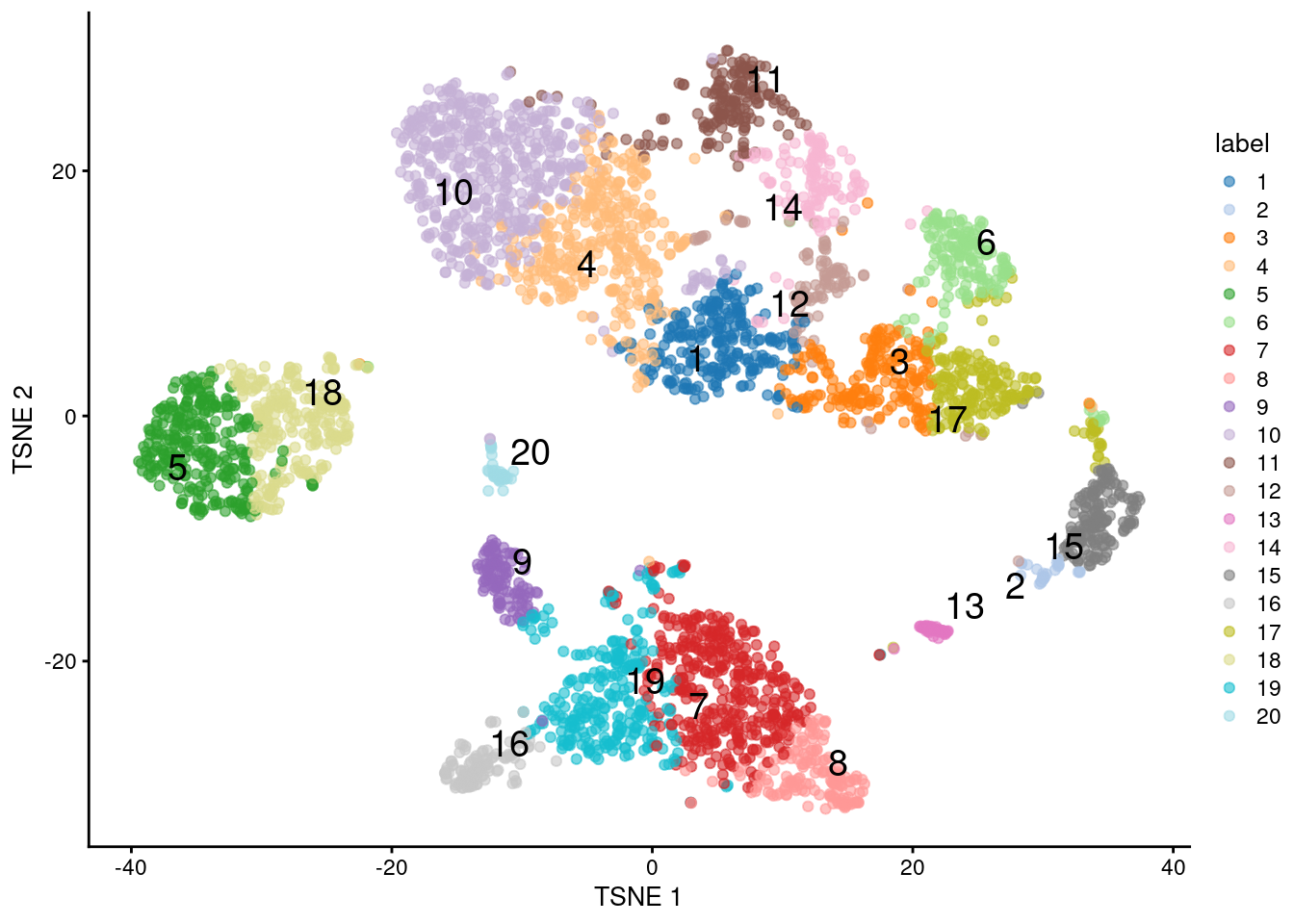
Figure 5.5: \(t\)-SNE plot of the 10X PBMC dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from \(k\)-means clustering with \(k=20\).
For larger datasets, we can use a variant of this approach named mini-batch \(k\)-means from the mbkmeans package.
At each iteration, we only update the cluster assignments and centroid positions for a small subset of the observations.
This reduces memory usage and computational time - especially when not all of the observations are informative for convergence - and supports parallelization via BiocParallel.
Using this variant is as simple as switching to a MbkmeansParam() object in our clusterCells() call:
set.seed(100)
clust.mbkmeans <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=MbkmeansParam(centers=10))
table(clust.mbkmeans)## clust.mbkmeans
## 1 2 3 4 5 6 7 8 9 10
## 304 339 490 46 304 560 16 176 727 10235.3.3 In two-step procedures
By itself, \(k\)-means suffers from several shortcomings that reduce its appeal for obtaining interpretable clusters:
- It implicitly favors spherical clusters of equal radius. This can lead to unintuitive partitionings on real datasets that contain groupings with irregular sizes and shapes.
- The number of clusters \(k\) must be specified beforehand and represents a hard cap on the resolution of the clustering.. For example, setting \(k\) to be below the number of cell types will always lead to co-clustering of two cell types, regardless of how well separated they are. In contrast, other methods like graph-based clustering will respect strong separation even if the relevant resolution parameter is set to a low value.
- It is dependent on the randomly chosen initial coordinates. This requires multiple runs to verify that the clustering is stable.
However, these concerns are less relevant when \(k\)-means is being used for vector quantization.
In this application, \(k\)-means is used as a prelude to more sophisticated and interpretable - but computationally expensive - clustering algorithms.
The clusterCells() function supports a “two-step” mode where \(k\)-means is initially used to obtain representative centroids that are subjected to graph-based clustering.
Each cell is then placed in the same graph-based cluster that its \(k\)-means centroid was assigned to (Figure 5.6).
# Setting the seed due to the randomness of k-means.
set.seed(0101010)
kgraph.clusters <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=TwoStepParam(
first=KmeansParam(centers=1000),
second=NNGraphParam(k=5)
)
)
table(kgraph.clusters)## kgraph.clusters
## 1 2 3 4 5 6 7 8 9 10 11 12
## 191 854 506 541 541 892 46 120 29 132 47 86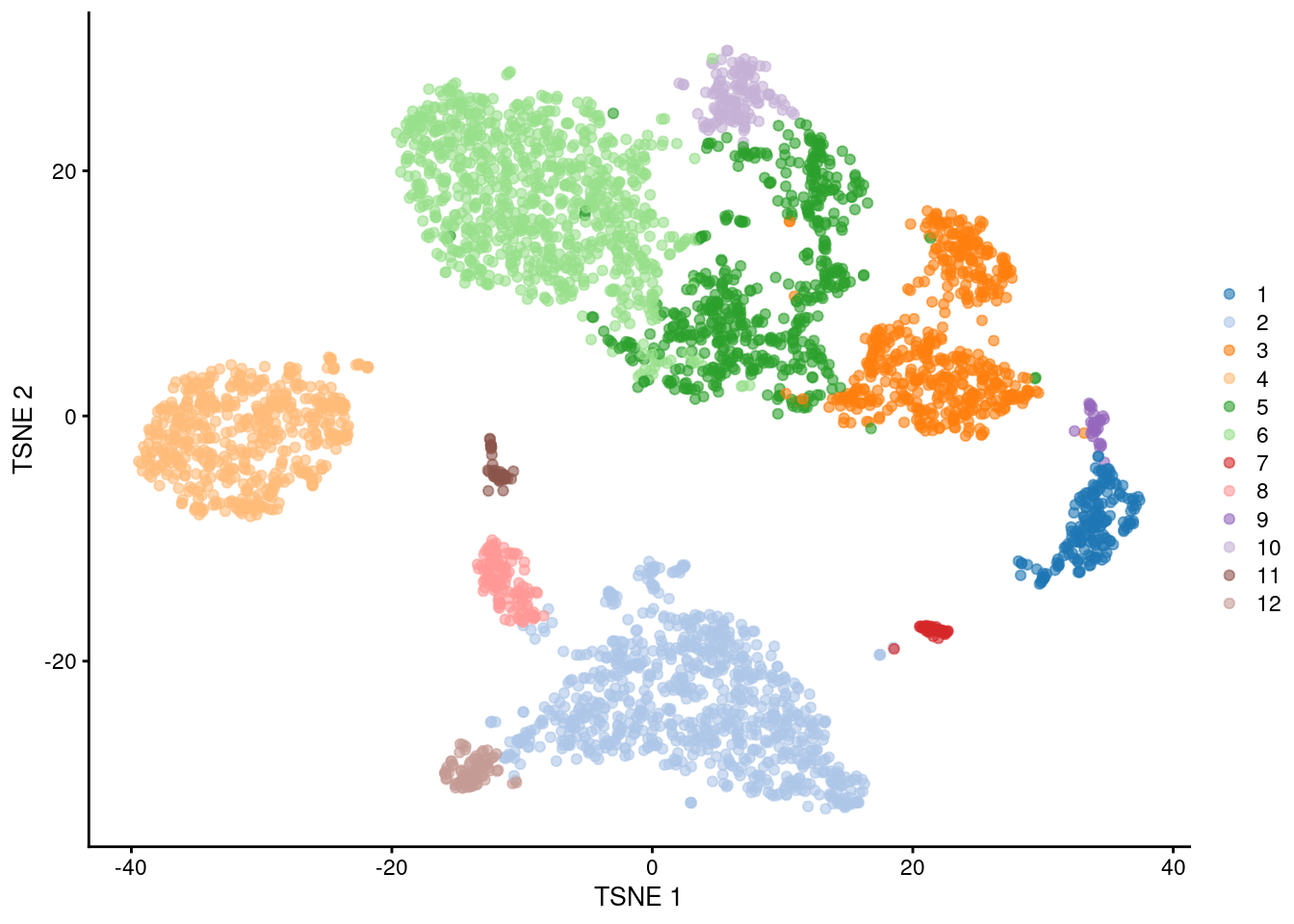
Figure 5.6: \(t\)-SNE plot of the PBMC dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from combined \(k\)-means/graph-based clustering.
The obvious benefit of this approach over direct graph-based clustering is the speed improvement. We avoid the need to identifying nearest neighbors for each cell and the construction of a large intermediate graph, while benefiting from the relative interpretability of graph-based clusters compared to those from \(k\)-means. This approach also mitigates the “inflation” effect discussed in Section 5.2. Each centroid serves as a representative of a region of space that is roughly similar in volume, ameliorating differences in cell density that can cause (potentially undesirable) differences in resolution.
The choice of the number of \(k\)-means clusters determines the trade-off between speed and fidelity.
Larger values provide a more faithful representation of the underlying distribution of cells,
at the cost of requiring more computational work by the second-step clustering procedure.
Note that the second step operates on the centroids, so increasing clusters= may have further implications if the second-stage procedure is sensitive to the total number of input observations.
For example, increasing the number of centroids would require an concomitant increase in k= (the number of neighbors in graph construction) to maintain the same level of resolution in the final output.
5.4 Hierarchical clustering
5.4.1 Background
Hierarchical clustering is an old technique that arranges samples into a hierarchy based on their relative similarity to each other. Most implementations do so by joining the most similar samples into a new cluster, then joining similar clusters into larger clusters, and so on, until all samples belong to a single cluster. This process yields obtain a dendrogram that defines clusters with progressively increasing granularity. Variants of hierarchical clustering methods primarily differ in how they choose to perform the agglomerations. For example, complete linkage aims to merge clusters with the smallest maximum distance between their elements, while Ward’s method aims to minimize the increase in within-cluster variance.
In the context of scRNA-seq, the main advantage of hierarchical clustering lies in the production of the dendrogram. This is a rich summary that quantitatively captures the relationships between subpopulations at various resolutions. Cutting the dendrogram at high resolution is also guaranteed to yield clusters that are nested within those obtained at a low-resolution cut; this can be helpful for interpretation, as discussed in Section 5.5. The dendrogram is also a natural representation of the data in situations where cells have descended from a relatively recent common ancestor.
In practice, hierarchical clustering is too slow to be used for anything but the smallest scRNA-seq datasets. Most implementations require a cell-cell distance matrix that is prohibitively expensive to compute for a large number of cells. Greedy agglomeration is also likely to result in a quantitatively suboptimal partitioning (as defined by the agglomeration measure) at higher levels of the dendrogram when the number of cells and merge steps is high. Nonetheless, we will still demonstrate the application of hierarchical clustering here as it can be useful when combined with vector quantization techniques like \(k\)-means.
5.4.2 Implementation
The PBMC dataset is too large to use directly in hierarchical clustering, requiring a two-step approach to compress the observations instead (Section 5.3.3). For the sake of simplicity, we will demonstrate on the smaller 416B dataset instead.
#--- loading ---#
library(scRNAseq)
sce.416b <- LunSpikeInData(which="416b")
sce.416b$block <- factor(sce.416b$block)
#--- gene-annotation ---#
library(AnnotationHub)
ens.mm.v97 <- AnnotationHub()[["AH73905"]]
rowData(sce.416b)$ENSEMBL <- rownames(sce.416b)
rowData(sce.416b)$SYMBOL <- mapIds(ens.mm.v97, keys=rownames(sce.416b),
keytype="GENEID", column="SYMBOL")
rowData(sce.416b)$SEQNAME <- mapIds(ens.mm.v97, keys=rownames(sce.416b),
keytype="GENEID", column="SEQNAME")
library(scater)
rownames(sce.416b) <- uniquifyFeatureNames(rowData(sce.416b)$ENSEMBL,
rowData(sce.416b)$SYMBOL)
#--- quality-control ---#
mito <- which(rowData(sce.416b)$SEQNAME=="MT")
stats <- perCellQCMetrics(sce.416b, subsets=list(Mt=mito))
qc <- quickPerCellQC(stats, percent_subsets=c("subsets_Mt_percent",
"altexps_ERCC_percent"), batch=sce.416b$block)
sce.416b <- sce.416b[,!qc$discard]
#--- normalization ---#
library(scran)
sce.416b <- computeSumFactors(sce.416b)
sce.416b <- logNormCounts(sce.416b)
#--- variance-modelling ---#
dec.416b <- modelGeneVarWithSpikes(sce.416b, "ERCC", block=sce.416b$block)
chosen.hvgs <- getTopHVGs(dec.416b, prop=0.1)
#--- batch-correction ---#
library(limma)
assay(sce.416b, "corrected") <- removeBatchEffect(logcounts(sce.416b),
design=model.matrix(~sce.416b$phenotype), batch=sce.416b$block)
#--- dimensionality-reduction ---#
sce.416b <- runPCA(sce.416b, ncomponents=10, subset_row=chosen.hvgs,
exprs_values="corrected", BSPARAM=BiocSingular::ExactParam())
set.seed(1010)
sce.416b <- runTSNE(sce.416b, dimred="PCA", perplexity=10)## class: SingleCellExperiment
## dim: 46604 185
## metadata(0):
## assays(3): counts logcounts corrected
## rownames(46604): 4933401J01Rik Gm26206 ... CAAA01147332.1
## CBFB-MYH11-mcherry
## rowData names(4): Length ENSEMBL SYMBOL SEQNAME
## colnames(185): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
## SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
## SLX-11312.N712_S507.H5H5YBBXX.s_8.r_1
## SLX-11312.N712_S517.H5H5YBBXX.s_8.r_1
## colData names(10): Source Name cell line ... block sizeFactor
## reducedDimNames(2): PCA TSNE
## mainExpName: endogenous
## altExpNames(2): ERCC SIRVWe use a HclustParam object to instruct clusterCells() to perform hierarchical clustering on the top PCs.
Specifically, it computes a cell-cell distance matrix using the top PCs and then applies Ward’s minimum variance method to obtain a dendrogram.
When visualized in Figure 5.7, we see a clear split in the population caused by oncogene induction.
While both Ward’s method and the default complete linkage yield compact clusters, we prefer the former it is less affected by differences in variance between clusters.
hclust.416b <- clusterCells(sce.416b, use.dimred="PCA",
BLUSPARAM=HclustParam(method="ward.D2"), full=TRUE)
tree.416b <- hclust.416b$objects$hclust
# Making a prettier dendrogram.
library(dendextend)
tree.416b$labels <- seq_along(tree.416b$labels)
dend <- as.dendrogram(tree.416b, hang=0.1)
combined.fac <- paste0(sce.416b$block, ".",
sub(" .*", "", sce.416b$phenotype))
labels_colors(dend) <- c(
"20160113.wild"="blue",
"20160113.induced"="red",
"20160325.wild"="dodgerblue",
"20160325.induced"="salmon"
)[combined.fac][order.dendrogram(dend)]
plot(dend)
Figure 5.7: Hierarchy of cells in the 416B data set after hierarchical clustering, where each leaf node is a cell that is coloured according to its oncogene induction status (red is induced, blue is control) and plate of origin (light or dark).
To obtain explicit clusters, we “cut” the tree by removing internal branches such that every subtree represents a distinct cluster.
This is most simply done by removing internal branches above a certain height of the tree, as performed by the cutree() function.
A more sophisticated variant of this approach is implemented in the dynamicTreeCut package,
which uses the shape of the branches to obtain a better partitioning for complex dendrograms (Figure 5.8).
We enable this option by setting cut.dynamic=TRUE, with additional tweaking of the deepSplit= parameter to control the resolution of the resulting clusters.
hclust.dyn <- clusterCells(sce.416b, use.dimred="PCA",
BLUSPARAM=HclustParam(method="ward.D2", cut.dynamic=TRUE,
cut.params=list(minClusterSize=10, deepSplit=1)))
table(hclust.dyn)## hclust.dyn
## 1 2 3 4
## 78 69 24 14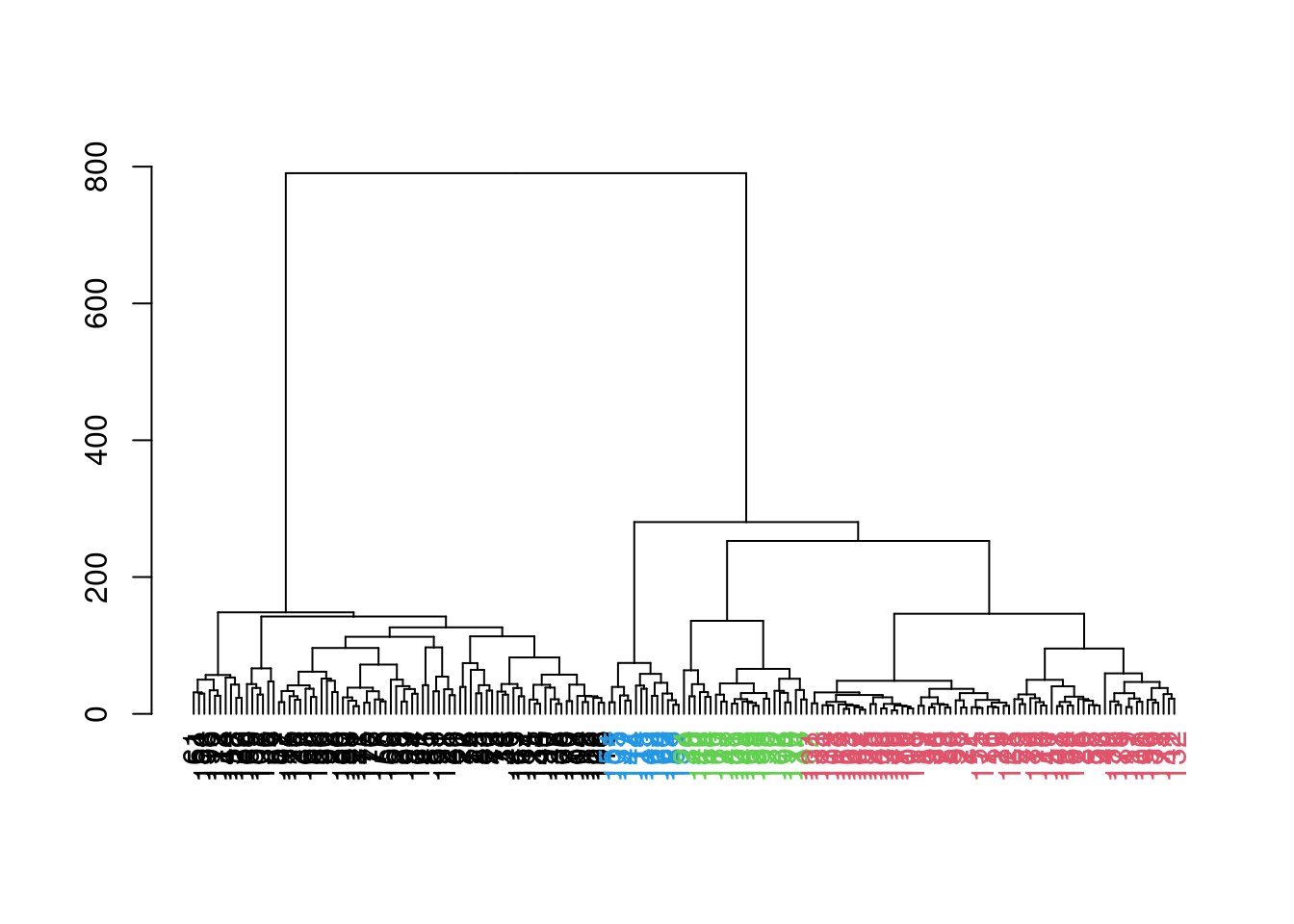
Figure 5.8: Hierarchy of cells in the 416B data set after hierarchical clustering, where each leaf node is a cell that is coloured according to its assigned cluster identity from a dynamic tree cut.
This generally corresponds well to the grouping of cells on a \(t\)-SNE plot (Figure 5.9). Cluster 2 is split across two visual clusters in the plot but we attribute this to a distortion introduced by \(t\)-SNE, given that this cluster actually has the highest average silhouette width (Advanced Section 5.2.2).
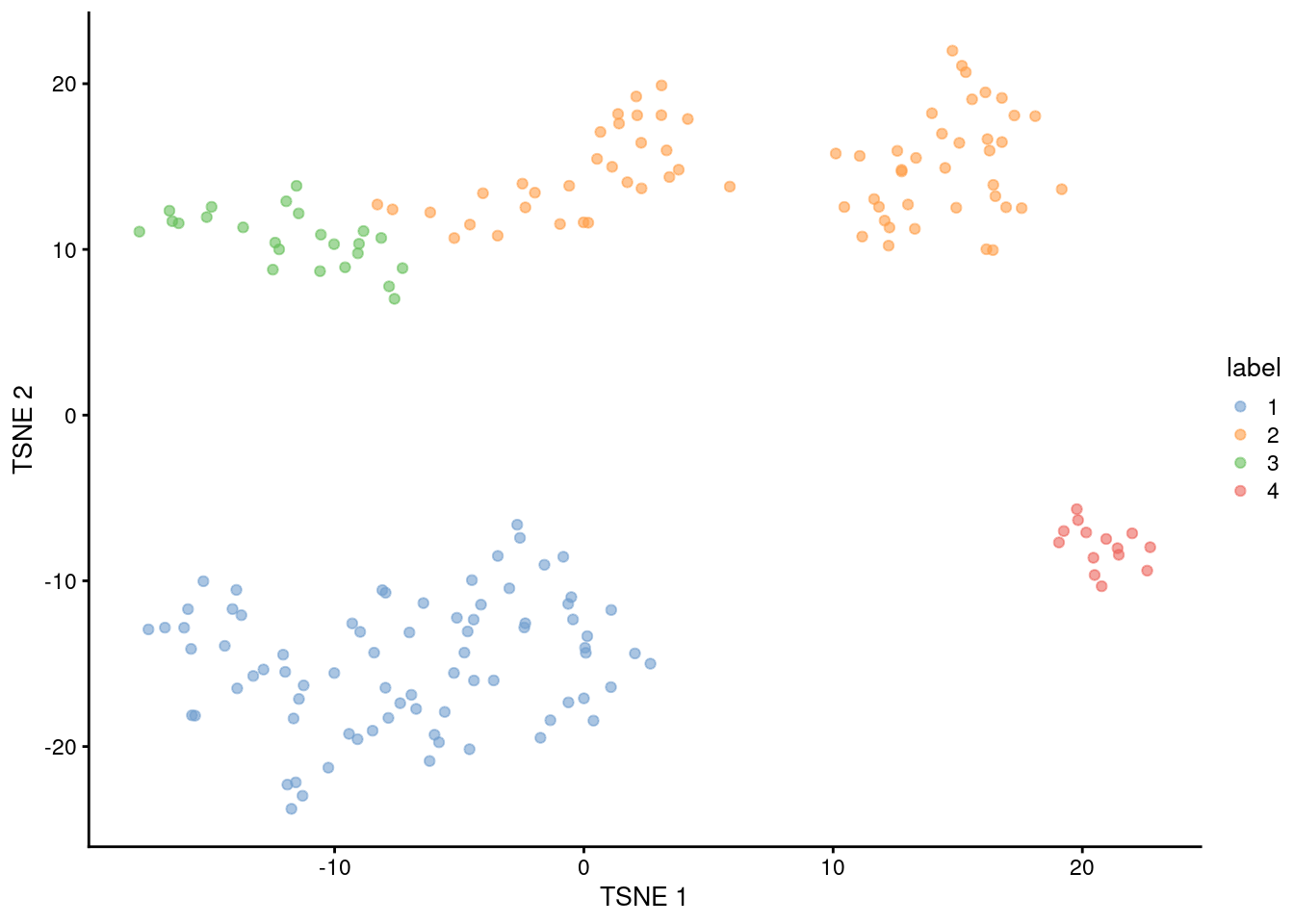
Figure 5.9: \(t\)-SNE plot of the 416B dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from hierarchical clustering.
5.4.3 In two-step procedures, again
Returning to our PBMC example, we can use a two-step approach to perform hierarchical clustering on the representative centroids (Figure 5.10). This avoids the construction of a distance matrix across all cells for faster computation.
# Setting the seed due to the randomness of k-means.
set.seed(1111)
khclust.info <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=TwoStepParam(
first=KmeansParam(centers=1000),
second=HclustParam(method="ward.D2", cut.dynamic=TRUE,
cut.param=list(deepSplit=3)) # for higher resolution.
),
full=TRUE
)
table(khclust.info$clusters)##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## 649 374 347 328 281 243 218 223 161 157 172 133 135 167 93 117 72 115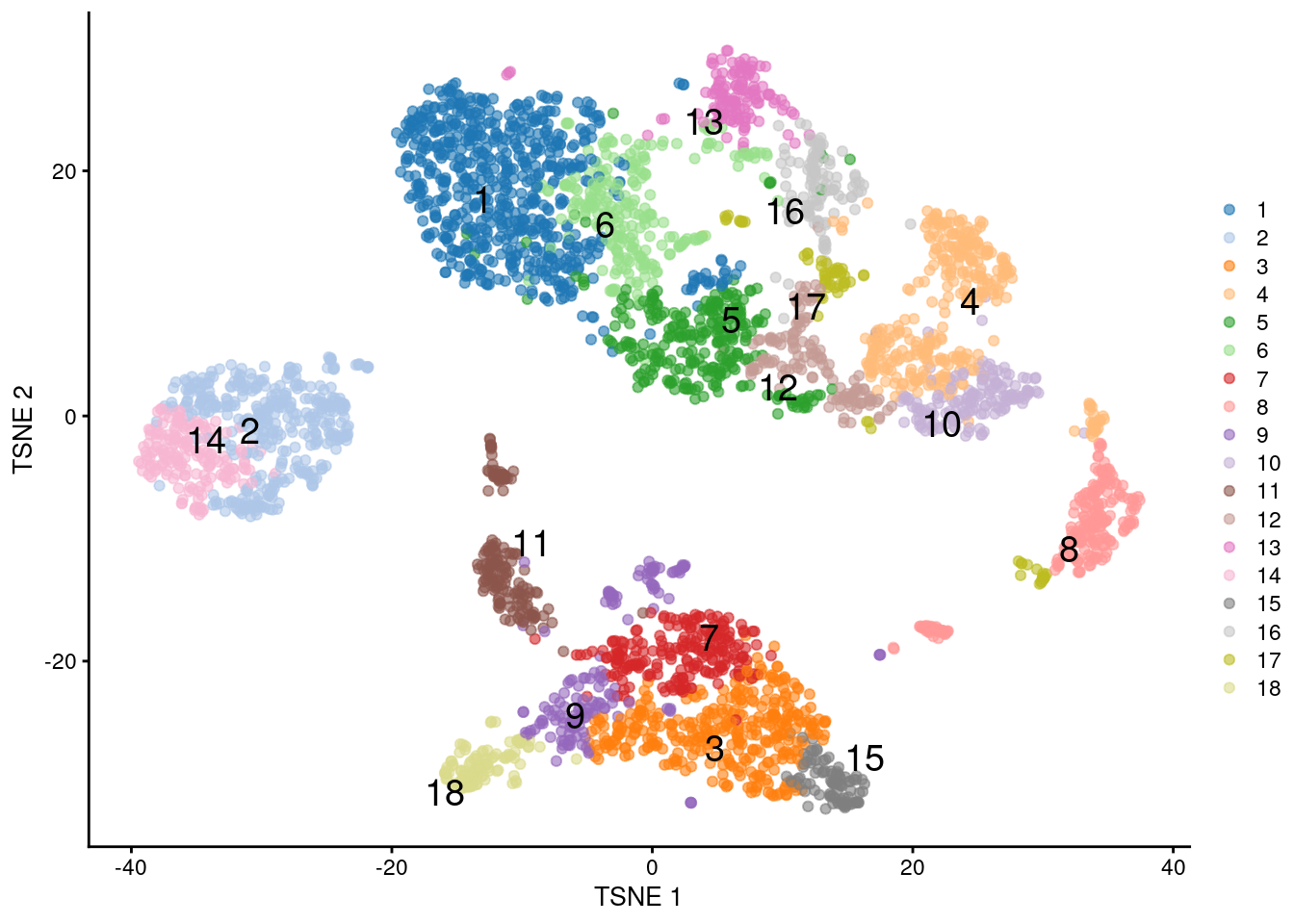
Figure 5.10: \(t\)-SNE plot of the PBMC dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from combined \(k\)-means/hierarchical clustering.
With a little bit of work, we can also examine the dendrogram constructed on the centroids (Figure 5.11). This provides a more quantitative visualization of the relative similarities between the different subpopulations.
k.stats <- khclust.info$objects$first
tree.pbmc <- khclust.info$objects$second$hclust
m <- match(as.integer(tree.pbmc$labels), k.stats$cluster)
final.clusters <- khclust.info$clusters[m]
# TODO: expose scater color palette for easier re-use,
# given that the default colors start getting recycled.
dend <- as.dendrogram(tree.pbmc, hang=0.1)
labels_colors(dend) <- as.integer(final.clusters)[order.dendrogram(dend)]
plot(dend)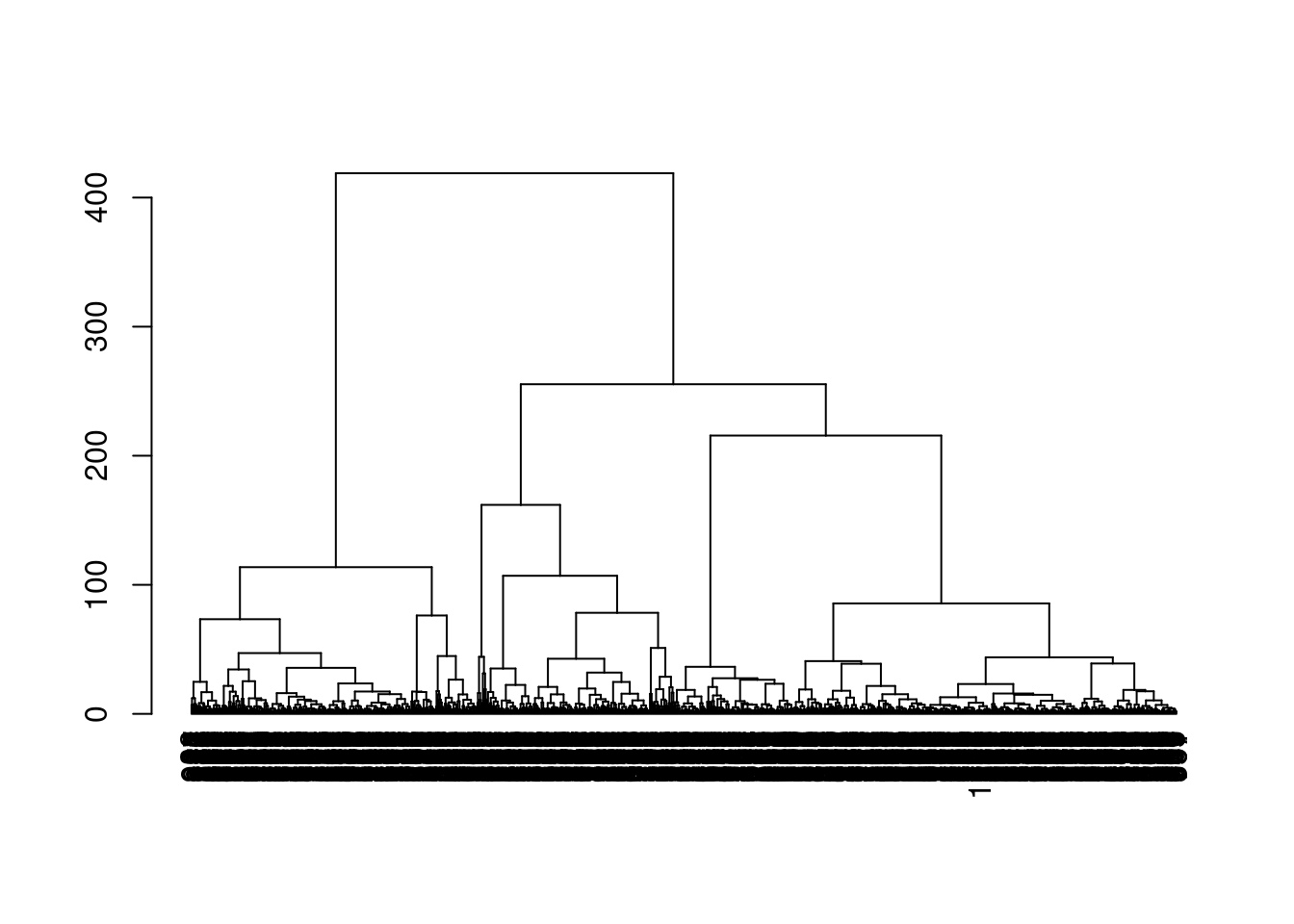
Figure 5.11: Dendrogram of the \(k\)-mean centroids after hierarchical clustering in the PBMC dataset. Each leaf node represents a representative cluster of cells generated by \(k\)-mean clustering.
As an aside, the same approach can be used to speed up any clustering method based on a distance matrix.
For example, we could subject our \(k\)-means centroids to clustering by affinity propagation (Frey and Dueck 2007).
In this procedure, each sample (i.e., centroid) chooses itself or another sample as its “exemplar”,
with the suitability of the choice dependent on the distance between the samples, other potential exemplars for each sample, and the other samples with the same chosen exemplar.
Iterative updates of these choices yields a set of clusters where each cluster is defined from the samples assigned to the same exemplar (Figure 5.12)
Unlike hierarchical clustering, this does not provide a dendrogram, but it also avoids the extra complication of a tree cut -
resolution is primarily controlled via the q= parameter, which defines the strength with which a sample considers itself as an exemplar and thus forms its own cluster.
# Setting the seed due to the randomness of k-means.
set.seed(1111)
kaclust.info <- clusterCells(sce.pbmc, use.dimred="PCA",
BLUSPARAM=TwoStepParam(
first=KmeansParam(centers=1000),
second=AffinityParam(q=0.1) # larger q => more clusters
),
full=TRUE
)
table(kaclust.info$clusters)##
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## 847 144 392 93 405 264 170 209 379 187 24 20 45 121 536 27 64 58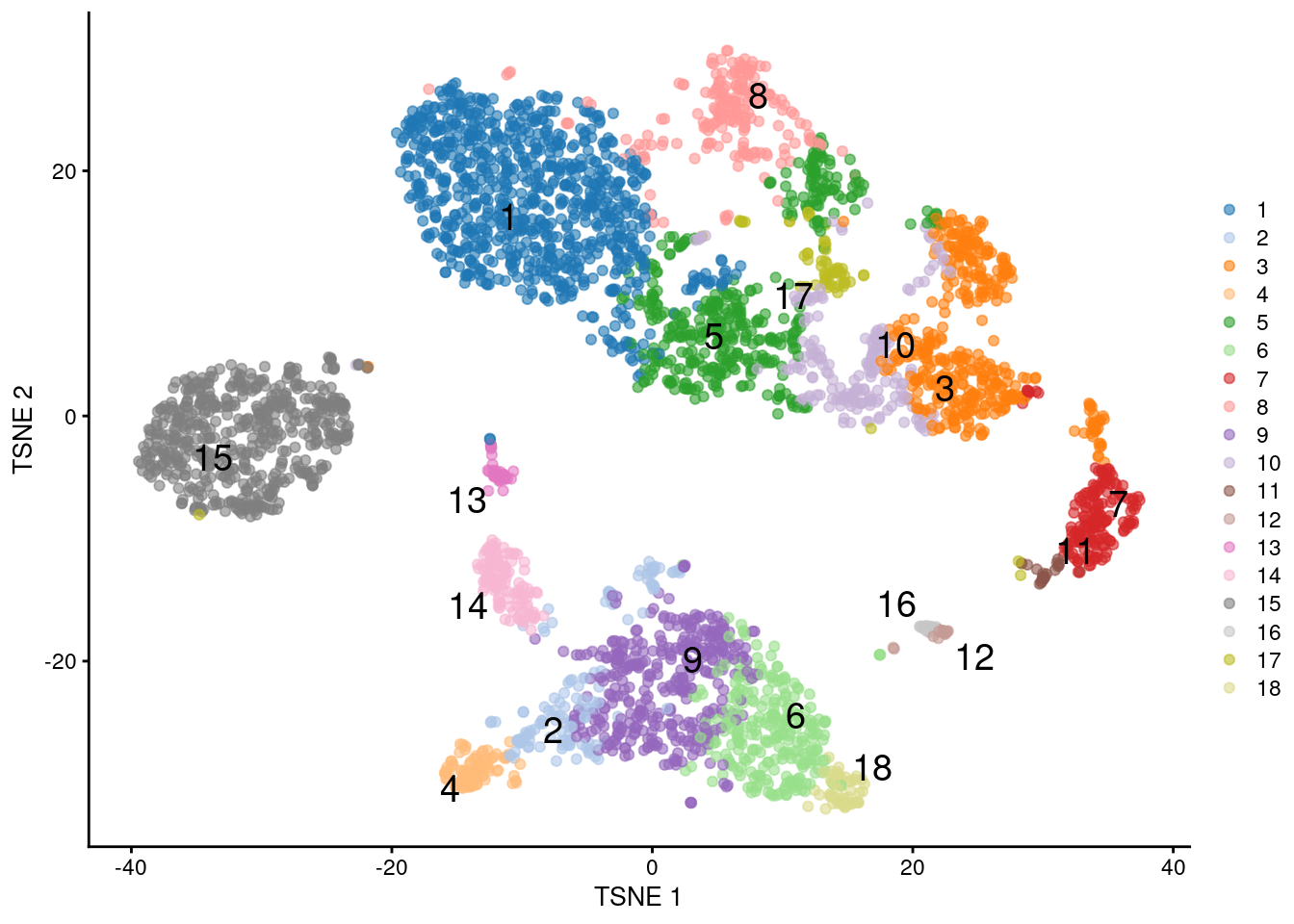
Figure 5.12: \(t\)-SNE plot of the PBMC dataset, where each point represents a cell and is coloured according to the identity of the assigned cluster from combined \(k\)-means/affinity propagation clustering.
5.5 Subclustering
Another simple approach to improving resolution is to repeat the feature selection and clustering within a single cluster. This aims to select HVGs and PCs that are more relevant to internal structure, improving resolution by avoiding noise from unnecessary features. Subsetting also encourages clustering methods to separate cells according to more modest heterogeneity in the absence of distinct subpopulations. We demonstrate with a cluster of putative memory T cells from the PBMC dataset, identified according to several markers (Figure 5.13).
clust.full <- clusterCells(sce.pbmc, use.dimred="PCA")
plotExpression(sce.pbmc, features=c("CD3E", "CCR7", "CD69", "CD44"),
x=I(clust.full), colour_by=I(clust.full))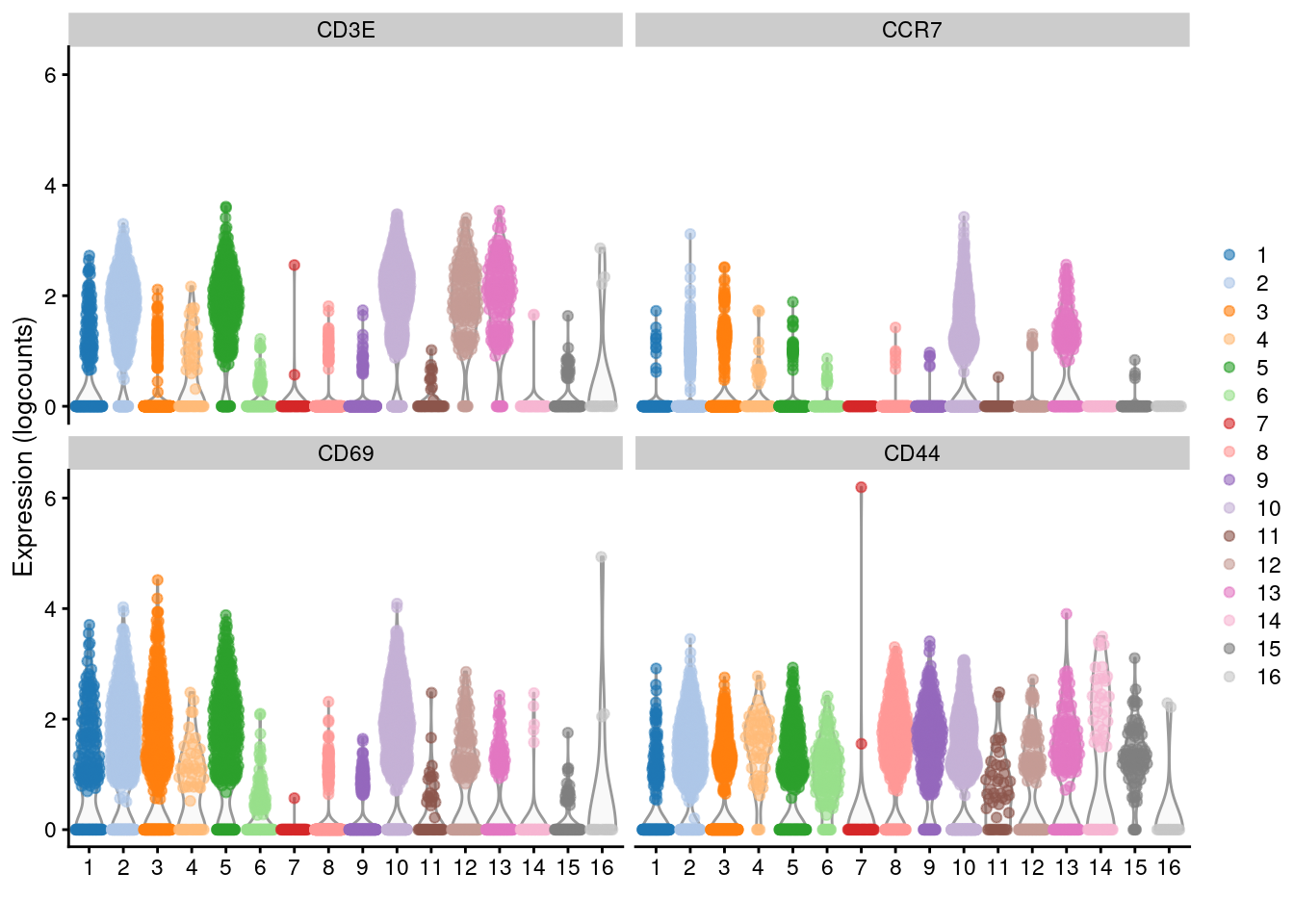
Figure 5.13: Distribution of log-normalized expression values for several T cell markers within each cluster in the 10X PBMC dataset. Each cluster is color-coded for convenience.
# Repeating modelling and PCA on the subset.
memory <- 10L
sce.memory <- sce.pbmc[,clust.full==memory]
dec.memory <- modelGeneVar(sce.memory)
sce.memory <- denoisePCA(sce.memory, technical=dec.memory,
subset.row=getTopHVGs(dec.memory, n=5000))We apply graph-based clustering within this memory subset to obtain CD4+ and CD8+ subclusters (Figure 5.14). Admittedly, the expression of CD4 is so low that the change is rather modest, but the interpretation is clear enough.
g.memory <- buildSNNGraph(sce.memory, use.dimred="PCA")
clust.memory <- igraph::cluster_walktrap(g.memory)$membership
plotExpression(sce.memory, features=c("CD8A", "CD4"),
x=I(factor(clust.memory)))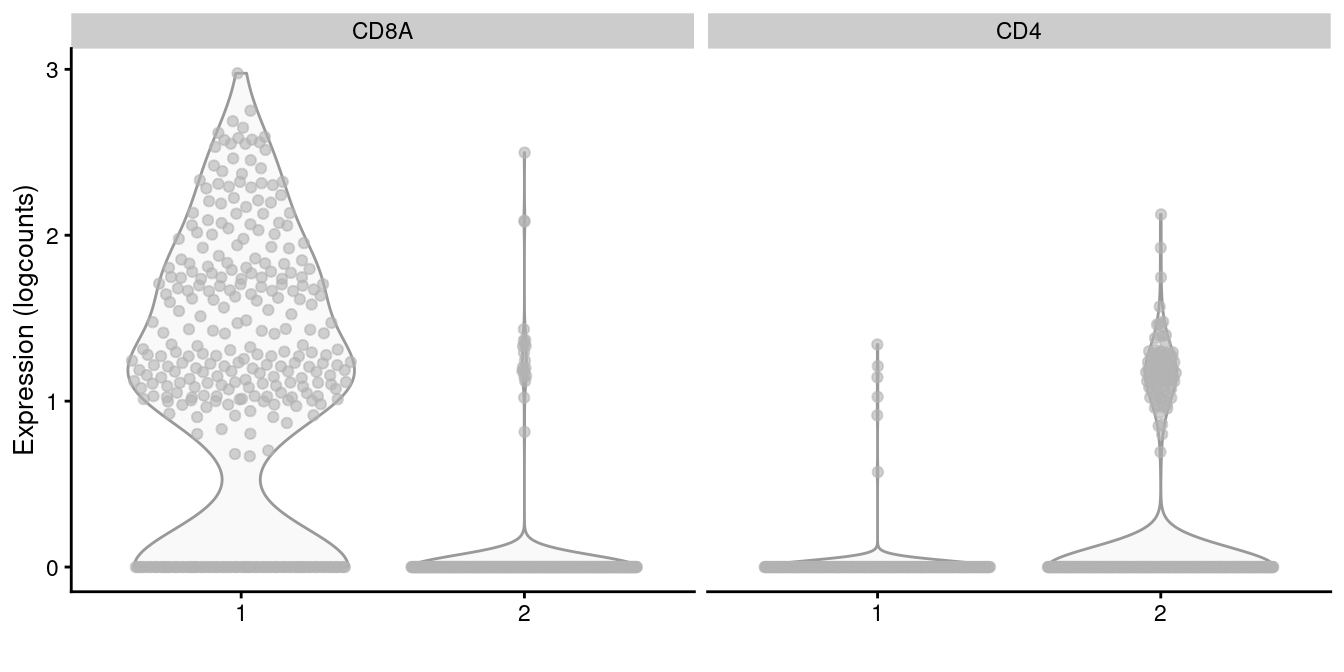
Figure 5.14: Distribution of CD4 and CD8A log-normalized expression values within each cluster in the memory T cell subset of the 10X PBMC dataset.
For subclustering analyses, it is helpful to define a customized function that calls our desired algorithms to obtain a clustering from a given SingleCellExperiment.
This function can then be applied multiple times on different subsets without having to repeatedly copy and modify the code for each subset.
For example, quickSubCluster() loops over all subsets and executes this user-specified function to generate a list of SingleCellExperiment objects containing the subclustering results.
(Of course, the downside is that this assumes that a similar analysis is appropriate for each subset.
If different subsets require extensive reparametrization, copying the code may actually be more straightforward.)
set.seed(1000010)
subcluster.out <- quickSubCluster(sce.pbmc, groups=clust.full,
prepFUN=function(x) { # Preparing the subsetted SCE for clustering.
dec <- modelGeneVar(x)
input <- denoisePCA(x, technical=dec,
subset.row=getTopHVGs(dec, prop=0.1),
BSPARAM=BiocSingular::IrlbaParam())
},
clusterFUN=function(x) { # Performing the subclustering in the subset.
g <- buildSNNGraph(x, use.dimred="PCA", k=20)
igraph::cluster_walktrap(g)$membership
}
)
# One SingleCellExperiment object per parent cluster:
names(subcluster.out)## [1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10" "11" "12" "13" "14" "15"
## [16] "16"##
## 1.1 1.2 1.3 1.4 1.5 1.6
## 28 22 34 62 11 48Subclustering is a general and conceptually straightforward procedure for increasing resolution. It can also simplify the interpretation of the subclusters, which only need to be considered in the context of the parent cluster’s identity - for example, we did not have to re-identify the cells in cluster 10 as T cells. However, this is a double-edged sword as it is difficult for practitioners to consider the uncertainty of identification for parent clusters when working with deep nesting. If cell types or states span cluster boundaries, conditioning on the putative cell type identity of the parent cluster can encourage the construction of a “house of cards” of cell type assignments, e.g., where a subcluster of one parent cluster is actually contamination from a cell type in a separate parent cluster.
Session Info
R version 4.3.0 RC (2023-04-13 r84269)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 22.04.2 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.17-bioc/R/lib/libRblas.so
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] apcluster_1.4.10 dendextend_1.17.1
[3] pheatmap_1.0.12 bluster_1.10.0
[5] scater_1.28.0 ggplot2_3.4.2
[7] scran_1.28.0 scuttle_1.10.0
[9] SingleCellExperiment_1.22.0 SummarizedExperiment_1.30.0
[11] Biobase_2.60.0 GenomicRanges_1.52.0
[13] GenomeInfoDb_1.36.0 IRanges_2.34.0
[15] S4Vectors_0.38.0 BiocGenerics_0.46.0
[17] MatrixGenerics_1.12.0 matrixStats_0.63.0
[19] BiocStyle_2.28.0 rebook_1.10.0
loaded via a namespace (and not attached):
[1] bitops_1.0-7 gridExtra_2.3
[3] CodeDepends_0.6.5 rlang_1.1.0
[5] magrittr_2.0.3 compiler_4.3.0
[7] dir.expiry_1.8.0 DelayedMatrixStats_1.22.0
[9] vctrs_0.6.2 pkgconfig_2.0.3
[11] fastmap_1.1.1 XVector_0.40.0
[13] labeling_0.4.2 utf8_1.2.3
[15] rmarkdown_2.21 graph_1.78.0
[17] ggbeeswarm_0.7.1 xfun_0.39
[19] zlibbioc_1.46.0 cachem_1.0.7
[21] beachmat_2.16.0 jsonlite_1.8.4
[23] highr_0.10 gmp_0.7-1
[25] DelayedArray_0.26.0 BiocParallel_1.34.0
[27] irlba_2.3.5.1 parallel_4.3.0
[29] cluster_2.1.4 R6_2.5.1
[31] bslib_0.4.2 RColorBrewer_1.1-3
[33] limma_3.56.0 benchmarkme_1.0.8
[35] ClusterR_1.3.0 jquerylib_0.1.4
[37] iterators_1.0.14 Rcpp_1.0.10
[39] bookdown_0.33 knitr_1.42
[41] Matrix_1.5-4 igraph_1.4.2
[43] tidyselect_1.2.0 yaml_2.3.7
[45] viridis_0.6.2 doParallel_1.0.17
[47] mbkmeans_1.16.0 codetools_0.2-19
[49] lattice_0.21-8 tibble_3.2.1
[51] withr_2.5.0 benchmarkmeData_1.0.4
[53] evaluate_0.20 pillar_1.9.0
[55] BiocManager_1.30.20 filelock_1.0.2
[57] foreach_1.5.2 generics_0.1.3
[59] RCurl_1.98-1.12 sparseMatrixStats_1.12.0
[61] munsell_0.5.0 scales_1.2.1
[63] glue_1.6.2 metapod_1.8.0
[65] tools_4.3.0 BiocNeighbors_1.18.0
[67] ScaledMatrix_1.8.0 locfit_1.5-9.7
[69] XML_3.99-0.14 cowplot_1.1.1
[71] grid_4.3.0 edgeR_3.42.0
[73] colorspace_2.1-0 GenomeInfoDbData_1.2.10
[75] beeswarm_0.4.0 BiocSingular_1.16.0
[77] vipor_0.4.5 cli_3.6.1
[79] rsvd_1.0.5 rappdirs_0.3.3
[81] fansi_1.0.4 viridisLite_0.4.1
[83] dplyr_1.1.2 gtable_0.3.3
[85] dynamicTreeCut_1.63-1 sass_0.4.5
[87] digest_0.6.31 ggrepel_0.9.3
[89] dqrng_0.3.0 farver_2.1.1
[91] htmltools_0.5.5 lifecycle_1.0.3
[93] httr_1.4.5 statmod_1.5.0 References
Frey, B. J., and D. Dueck. 2007. “Clustering by passing messages between data points.” Science 315 (5814): 972–76.
Ji, Z., and H. Ji. 2016. “TSCAN: Pseudo-time reconstruction and evaluation in single-cell RNA-seq analysis.” Nucleic Acids Res. 44 (13): e117.
Xu, C., and Z. Su. 2015. “Identification of cell types from single-cell transcriptomes using a novel clustering method.” Bioinformatics 31 (12): 1974–80.
Sten Linarrsson talked about this in SCG2018, but I don’t know where that work ended up. So this is what passes as a reference for the time being.↩︎